
.png&w=3840&q=75)
Consentimi di partire con un paio di domande a bruciapelo:
I tuoi sistemi di QA / Test / Sviluppo SAP recepiscono già le direttive GDPR?
O meglio, hai assicurato una corretta anonimizzazione dei dati riconducibili a persone fisiche presenti nel tuo database?
Se ancora non l’hai fatto, ti suggerisco di dare un occhio – tra gli altri – ai seguenti articoli introdotti dal GDPR (Regolamento generale sulla protezione dei dati – UE/2016/679):
– Art. 17: Diritto alla Cancellazione
– Diritto all’Oblio
– Art. 25: Protezione Dati fin dalla Progettazione e Protezione per Impostazione Predefinita
Prima però ti invito a proseguire nella lettura di questo blog, in cui illustrerò:
- I due requisiti fondamentali per un sistema di Quality a regola d’arte
- Un esempio di anonimizzazione troppo superficiale e generica
- Una strategia di anonimizzazione (o meglio pseudonimizzazione) intelligente sui dati personali dei tuoi sistemi SAP di Test

A mio modesto parere un sistema SAP di Quality, per poter legittimamente fregiarsi del titolo di “Quality” System (vale a dire Sistema di Qualità) deve possedere due requisiti imprescindibili:
-
Attualità del dato
-
Verosimiglianza del dato
Il primo obiettivo si raggiunge – più o meno agevolmente – mediante una schedulazione cadenzata dei refresh.
Magari agevolando le copie tramite il ricorso a uno scenario time-slice SAP TDMS (Test Data Migration System).
Grazie all’impostazione di una data di partenza (from-date) in fase di selezione dati, il TDMS consente – difatti – la creazione di un sistema di Test con un volume ridotto (leggasi meno costi di storage e più celerità nel trasferimento dati).
Il secondo aspetto – cioè avere un dato fittizio ma realistico – è reso ancor più importante dall’introduzione della GDPR. Al solito, la definizione di Wikipedia ci spiega bene cosa si intente per “fiction”:
Per fiction (termine inglese, letteralmente in italiano “finzione”, dal latino fingere, “formare”, “creare”) si intende la narrazione di eventi immaginari, diversamente dalla narrazione di eventi reali.
Idealmente, dobbiamo essere in grado di mettere in piedi una “vera” fiction (notate l’ossimoro) nei nostri ambienti di Test, Sviluppo, Sandbox. Etc.… Dobbiamo ri-mappare i dati personali di persone fisiche reali, con dati personali fittizi ma realistici. In questo modo saremo in grado di:
- Rispettare il diritto alla cancellazione e alla Privacy by Design della GDPR
- Ricreare dati personali verosimili e adatti ad eseguire test significativi negli ambienti di quality
- Utilizzare i dati anonimizzati per attività di analisi e ricerca e per scopi dimostrativi.
Due esempi successivi aiutano a chiarire meglio il concetto.

Qui di seguito riporto un caso di anonimizzazione che ho visto implementato nel sistema di Quality di un cliente SAP:
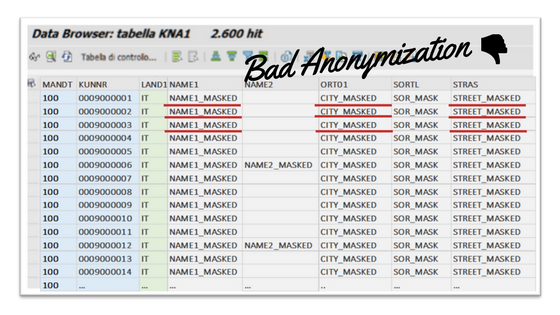
Cosa non funziona in questa strategia di scrambling? È qui ben evidente che i dati personali di TUTTI i clienti originari presenti a sistema, sono stati convertiti – in modo piuttosto sbrigativo – martellando valori FISSI nei campi rilevanti.
Come conseguenza di questa anonimizzazione a tappeto sui dati personi, ci ritroveremo a sistema N anagrafiche clienti con:
- Stesso nome e cognome
- Stesso Indirizzo (Comune, via, CAP; etc.…)
- Stessi dati personali
- Stessi etc. etc.
Potremmo mai affermare che questo sistema di Quality sia impostato per eseguire test significativi? Converrai come in realtà non lo sia affatto! Ad esempio, se volessimo testare un flusso di consegna e pianificare la miglior rotta di trasporto, scopriremmo che tutti i clienti hanno ora il medesimo indirizzo:
- Città = CITY_MASKED
- Indirizzo = STREET_MASKED
Ne deriva che le funzionalità del sistema di Quality soggetto a un’anonimizzazione troppo superficiale non potranno che essere limitate. Inoltre, assegnare valori fissi e ripetuti ai dati personali impedirà la possibilità di svolgere analisi e ricerche statistiche con correte campionature. L’ abrasione brutale dei dati personali determina infatti la perdita irreversibile di informazioni rilevanti per la valutazione delle distribuzioni stocastiche e delle correlazioni tra variabili (es. area geografica, fascia anagrafica, etc.…)

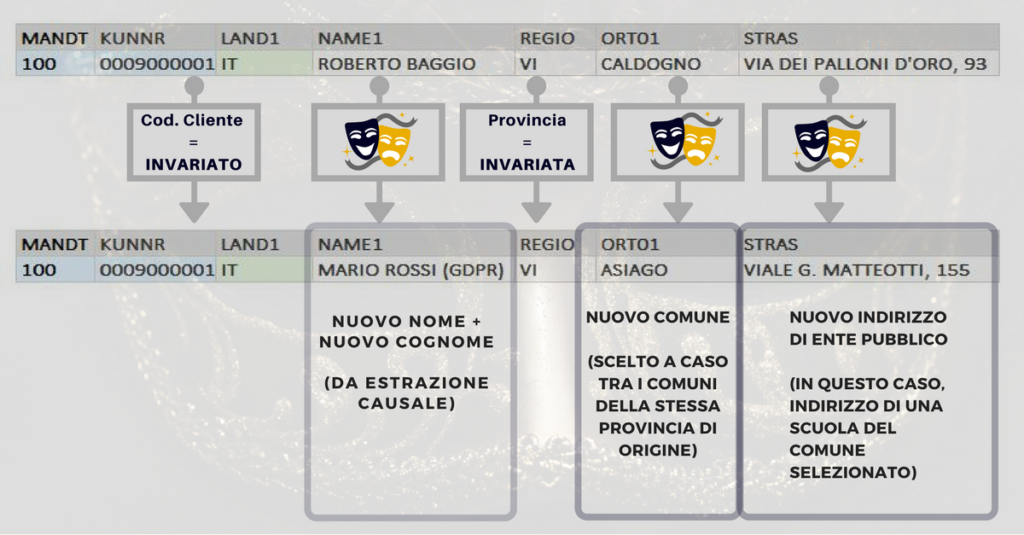
Vediamo ora un modo “virtuoso” di concepire l’anonimizzazione dei dati personali. Supponiamo che la tua società sia una azienda di telecomunicazioni ed abbia un contratto con il seguente cliente (reale):

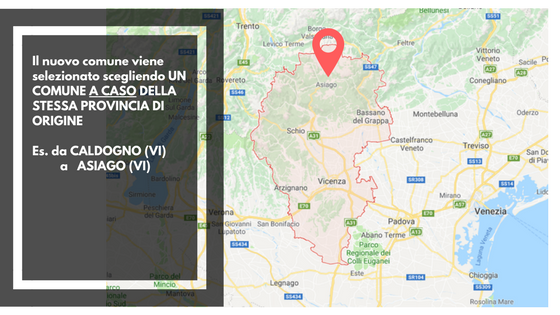
Una strategia di anonimizzazione diventa efficace quando riesce ad eliminare tutti i riferimenti alla persona fisica reale (Nome, Cognome, Indirizzo, email, numeri di telefono, codice fiscale, etc.…), sostituendola con una persona fittizia, avente tuttavia dei dati personali verosimili e vicini a quelli originali. Ad esempio, potremmo mantenere invariata la provincia di provenienza (in questo caso Vicenza) e sostituire l’indirizzo originale in modo casuale, andando a pescare tra i comuni della stessa provincia, e prendendo come nuovo indirizzo quello di un ente pubblico del comune appena selezionato (per esempio una scuola).
Naturalmente andremo a sostituire nome e cognome originali con una nuova identità, con estrazione casuale.
Ecco che il nostro cliente Roberto Baggio da Caldogno si trasforma – come per magia – nel Sig. Mario Rossi (GDPR) di Asiago, come riassunto nello schema seguente:
Conclusioni
L’implementazione di una strategia di anonimizzazione intelligente ci restituisce un sistema di quality che recepisce appieno i dettami della normativa GDPR. Al tempo stesso il sistema risulta fruibile in tutte le sue funzionalità grazie alla verosimiglianza dei dati personali modificati. In Inquaero siamo in grado di implementare lo scenario descritto con in due modalità:
-
Estensione ad-hoc dello scenario TDMS Scrambling
-
Software proprietario per anonimizzazione dati personali nei sistemi SAP
Con entrambe le soluzioni riusciamo a coprire e anonimizzare i dati personali di Business Partners, Clienti, Fornitori e Impiegati nel sistema, presenti sia nelle tabelle SAP standard, sia nelle tabelle custom (Y e Z). Per un approfondimento, contattaci all’indirizzo email info@inquaero.com

.png&w=3840&q=75)
.png&w=3840&q=75)