
.png&w=3840&q=75)
Ebbene Sì: “Il tuo sistema SAP contiene dati personali!”
Ben l’86% degli utenti SAP non conosce gli impatti del Regolamento GDPR sul proprio landscape di sistemi, e come cambierà l’accesso e il consumo dei dati personali in SAP. Fonte SAP User Group 2017 Research
L’entrata in vigore del Regolamento Ue 2016/679, meglio noto con l’acronico GDPR (General Data Protection Regulation) impone alle aziende l’adeguamento dei propri sistemi informativi alla direttiva europea (dal 25 Maggio 2018).
Ma cosa significa “in soldoni”?
Qual è l’impatto specifico sui sistemi SAP?
Andiamo con ordine, e cerchiamo di fare un po’ di chiarezza sugli interventi possibili per raggiungere (e mantenere) l’agognata compliance.
Tranquilli, non si corre pericolo di morte in caso di mancato adeguamento, ma il rischio di una sanzione salata sì: fino a 20 Milioni di Euro oppure una somma pari al 4% del fatturato mondiale annuo (scegliendo – tra i due importi – il valore più grande).
Premessa:
Le informazioni contenute in questo articolo vanno intese come guida generale e generica su alcune delle soluzioni software a supporto della GDPR , e non vanno interpretate come consulenza legale per ottemperare i requisiti di conformità imposti dalla normativa.
E’ responsabilità esclusiva del titolare e dei responsabili del trattamento dei dati adempiere agli obblighi di conformità.
Il percorso di seguito illustrato rappresenta quanto ho avuto modo di implementare in prima persona (o vedere applicato) nell’ambito di progetti di adeguamento di sistemi informativi SAP alla normativa GDPR.
CAPITOLO 1
Cosa va protetto: definire l’ambito
Come punto di partenza, occorre prima di tutto capire quali siano le conseguenze per l’IT del GDPR, con l’imposizione della protezione dei dati By Design e By Default.
 E’ indispensabile dunque conoscere – innanzitutto – che cosa va protetto e tutelato.
E’ indispensabile dunque conoscere – innanzitutto – che cosa va protetto e tutelato.
L’ambito del regolamento è chiaramente (e fortunatamente) circoscritto ai dati personali dei cittadini residenti nell’Unione Europea (in inglese si fa ricorso all’acronimo PII = Personally Identifiable Information)
E l’Articolo 4, Sez. 1 spiega bene cosa si intenda per dato personale, vale a dire:
qualsiasi informazione riguardante una persona fisica identificata o identificabile («interessato»);
si considera identificabile la persona fisica che può essere identificata, direttamente o indirettamente, con particolare riferimento a un identificativo come il nome, un numero di identificazione, dati relativi all’ubicazione, un identificativo online o a uno o più elementi caratteristici della sua identità fisica, fisiologica, genetica, psichica, economica, culturale o sociale…
Ora, per essere più precisi, ecco un elenco concreto di dati personali soggetti al regolamento GDPR e che possono essere distribuiti – in modo più o meno strutturato – all’interno di un landscape IT, più o meno complesso, e in particolare in ambienti SAP:
- Nome (e Iniziali)
- Cognome
- Data di Nascita
- Stato Civile
- Numero Social Security (Codice Fiscale / Tessera Sanitaria per l’Italia)
- Patente di Guida
- Indirizzo Email
- Numero di Telefono / Fax (personale e aziendale)
- Foto riconoscibile del soggetto
- Documenti Personali
- Dati GPS
- Storico pagamenti
- Stipendio
- Servizio Militare
- Fedina Penale
- Storico delle transazioni commerciali e finanziarie
- Conti Correnti Bancari
- Indirizzo IP dei dispositivi hardware in dotazione
- Dati personali Internet (Social Media link, URLs)
- Date ospedaliere (nascita, check-in, dimissione, decesso)
- Localizzazione geografica inferiore alla provincia (città e indirizzo)
- CV o dati inerenti la posizione lavorativa
- Segni particolari (tatuaggi, cicatrici)
- Percorso Studi
- Relazioni con Clienti
- Numero Carta di Credito
- Acquisiti effettuati con carte di credito
- Prestiti / Mutui e depositi bancari
- Orientamento politico
- Punteggio creditizio (Credit Score / Credit report)
- Identificatori Biometrici (es. DNA, impronta digitale, scansione iride, registrazioni timbro vocale)
- Informazioni sullo stato di salute / mediche (es, donazioni organi, trattamenti medici, disabilità)
La lista è lunga e sicuramente non pretende di essere esaustiva.
Ad ogni modo serve a far luce su cosa dobbiamo “proteggere”, vale a dire:
la persona fisica e i rispettivi dati personali.
Ribadisco il concetto, perché ho avuto modo di riscontrare un po’ di confusione in passato, nel corso di alcuni progetti GDPR.
Ad esempio, se un cliente di una data società è una persona giuridica (una S.p.A. o una S.r.l.), l’indirizzo dell’azienda cliente NON è un dato personale, e quindi non è soggetto al regolamento.
Questo non toglie che non possano essere applicate delle politiche di protezione anche a queste tipologie di dati.
Al contrario, i dati personali dei pazienti di una azienda ospedaliera rientrano chiaramente nell’ambito del regolamento GDPR. E vanno necessariamente identificati e protetti.
CAPITOLO 2
La documentazione GDPR
Oltre il 60% delle attività da svolgere in tema GDPR è relativo alla produzione di una documentazione completa, strutturata e consistente, che attesti la conformità alla normativa.
La restante parte di attività è invece inerente a come raggiungere e produrre detta documentazione, mantenendola aggiornata con il supporto di software per il monitoraggio degli accessi e dei processi, piuttosto che per la protezione dei dati personali tout court con strategie di mascheramento o anonimizzazione.
E’ importante precisare che per raggiungere la piena conformità al regolamento GDPR e produrre la dovuta documentazione non basta demandare tuto all’ IT manager.
La compliance deve coinvolgere tutti i vari dipartimenti interessati: quello legale, quello amministrativo, il marketing e naturalmente anche l’ ICT.
Un adeguato coinvolgimento delle parti interessate e una distribuzione capillare delle conoscenze (con corsi di formazione ad hoc), porteranno ad una gestione sistemica e strutturata del nuovo regolamento europeo all’interno dell’intera organizzazione.
 Quando si parla di documentazione, il Registro dei Trattamenti è la prima cosa che il Garante per la protezione dei dati personali richiederà in caso di verifiche.
Quando si parla di documentazione, il Registro dei Trattamenti è la prima cosa che il Garante per la protezione dei dati personali richiederà in caso di verifiche.
Il Registro rappresenta dunque il punto di partenza, la fotografia di come viene gestito il flusso dei dati personali all’interno dell’organizzazione.
In esso vengono censiti il titolare del trattamento e il responsabile della protezione dei dati.
La finalità del trattamento dati e la descrizione generale delle misure di sicurezza tecniche e organizzative completano poi il documento.
Il Registro Dei Trattamenti non rappresenta l’unica forma documentale necessaria, ma è accompagnato da ulteriori documenti di dettaglio e valutazione rischi vari quali Data Protection Impact Analysis (DPIA), Privacy Impact Analysis (PIA), etc… la cui descrizione esula dagli scopi del presente articolo.
Dopo aver rimarcato l’importanza e l’esigenza di mantenere una documentazione puntuale e aggiornata (il cosiddetto scudo di carta), passiamo ora ad analizzare e descrivere le soluzioni e i software a supporto del mondo SAP, nell’ottica della conformità al GDPR.
CAPITOLO 3
Come identificare i dati (fase di Discovery)
Come prima fase occorre censire e mappare i dati personali presenti all’interno del panorama dei sistemi informativi.
Nel merito di sistemi SAP, personalmente mi avvalgo di report di analisi custom che eseguono una scansione a livello di dominio o data-element SAP (domain scan).
La logica di fondo è quella di identificare tutte le tabelle del DataBase che contengono campi di dati personali (nome, indirizzo, carte di credito, etc. etc.), e poi verificare che dette tabelle siano effettivamente popolate.
Naturalmente, il supporto del cliente, che conosce vita morte e miracoli di quanto contenuto nel proprio sistema, è fondamentale per riuscire a identificare tutti i dati passibili di protezione.
 Per una discovery ancor più approfondita e mirata, SAP mette inoltre a disposizione il SAP Information Steward.
Per una discovery ancor più approfondita e mirata, SAP mette inoltre a disposizione il SAP Information Steward.
Il tool è concepito per la profilazione dei dati e la gestione dei metadati con il fine di tracciare e taggare i dati personali distribuiti e salvati nei vari ambienti SAP, ma anche extra-SAP.
Il principale vantaggio di SAP Information Steward consiste nel poter impostare e pilotare la ricerca da un unico sistema centrale, che raccoglie ed analizza i risultati in input provenienti da varie sorgenti (anche sistemi satelliti e non necessariamente SAP).
CAPITOLO 4
Come proteggere i sistemi produttivi (con SAP GRC e altro)
SAP GRC (leggi Governace + Risk Analysis + Compliance) è il compendio di soluzioni SAP per la gestione coordinata della sicurezza interna, attraverso l’identificazione automatizzata di problemi di comformità (compliance), e la previsione e l’intercettazione di potenziali rischi aziendali connessi all’uso del sistema.
Consideriamo un esempio tipico di problematiche da gestire in ambito GRC:
quando gli utenti dispongono di accessi e autorizzazioni troppo ampi, il rischio di creare danno all’azienda per violazione della conformità dei processi diventa concreto.
Ciò può avvenire sia volontariamente, se l’utente commette abuso intenzionale (ad es. sfruttando i privilegi per sottrarre indebitamente denaro o beni materiali), ma anche involontariamente, a seguito di un uso improprio delle transazioni a cui si è autorizzati (ad esempio se l’utente imputa un errore contabile o se salta, accidentalmente, una procedura obbligatoria di controllo qualità).
SAP ha ritenuto strategico il settore GRC fin dall’introduzione di normative a tutela della Compliance e della Segregazione dei Ruoli, come la Sarbanes-Oxely Act (o più semplicemente SOX), una legge federale del 2002, emanata negli Stati Uniti a seguito degli scandali contabili cha hanno visto coinvolte importanti organizzazioni come Enron e WorldCom.
In Italia invece, la spinta principale all’adozione di strumenti per il GRC arriva -più verosimilmente – dalla necessità di contenere i costi di conformità alle varie normative locali come la legge 231, 262 e la normativa sulla privacy 196.
Quindi, il concetto di GRC nasce e si sviluppa ben prima dell’avvento del GDPR.
Tuttavia, l’introduzione – a partire dal 25 Maggio 2018 – della normativa EU GDPR ha apportato ancor più linfa -se mai ve ne fosse bisogno – all’implementazione o all’ampliamento di progetti GRC in essere, con particolare focus sul monitoraggio dei flussi di business afferenti i dati personali dei cittadini dell’Unione.
La soluzione SAP GRC si suddivide in due macro-aree:
1 – Access Control
2 – Process Control
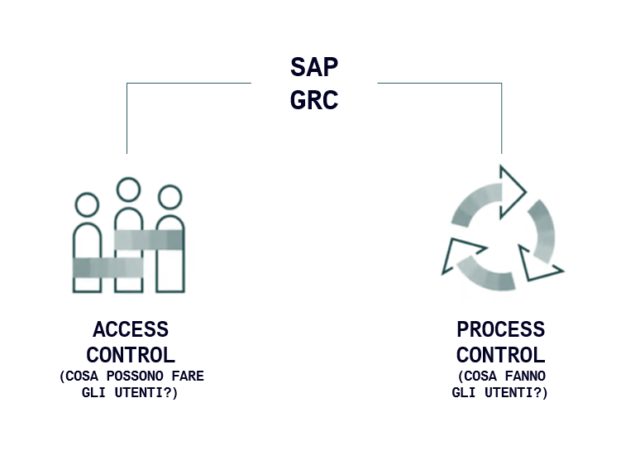
La differenza principale delle due aree di controllo può essere sintetizzata come segue:
Il controllo delle autorizzazioni in accesso (Access Control) si concentra su ciò che gli utenti possono fare (o meglio sono autorizzati a fare).
Mentre il Controllo di Processo (Process Control) focalizza l’attenzione su ciò che gli utenti stanno facendo a sistema.
Ad esempio, se il sistema accorda a un dato manager l’autorizzazione a leggere (in chiaro) i dati personali dei membri del proprio team senza una reale motivazione dettata dal business, il SAP GRC Access Control rileva la possibilità di una violazione GDPR della protezione del dato personale, e può generare un avviso.
Se poi, lo stesso manager accede, in effettivo, alle cartelle che contengono i dati personali e/o sensibili del proprio impiegato, allora il GRC Process Control entra in gioco per segnalare l’avvenuto lancio della transazione.
In aggiunta al GRC, un’altra soluzione interessante, e più recentemente introdotta da SAP, è l’User Interface (UI) Data Security: un approccio in due step per la protezione dalle intrusioni.
I due “passaggi”, che possono essere implementati sia contestualmente sia separatamente sono:
- UI Masking
- UI Logging (powered by Enterprise Threat Detection)
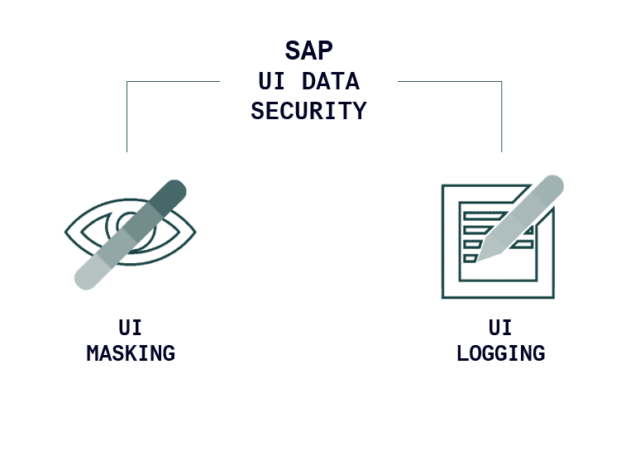
Naturalmente le funzionalità delle due soluzioni hanno un raggio di azione più ampio rispetto ai requisiti specifici GDPR.
Ad esempio, con UI Masking è possibile proteggere da occhi indiscreti qualunque tipo di informazione, quali i componenti di una Ricetta o Distinta Base, a tutela del segreto industriale e della Proprietà Intellettuale (IP) dell’azienda.
In ogni caso il concetto di UI Masking ben si adatta al requisito di protezione del dato personale espresso dal regolamento GDPR.
Infatti, è possibile gestire mascheramenti di tutti i dati personali identificati a livello di campo SAP (come il nome di un impiegato), e definire uno specifico ruolo autorizzativo da assegnare esclusivamente ai profili che necessitano la “processazione” del dato in chiaro.
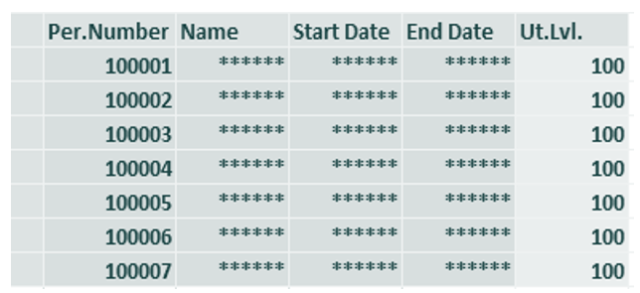
Pertanto, tutti gli utenti non autorizzati alla “visione in chiaro”, dopo il lancio di transazioni contenenti dati personali, si troveranno di fronte una serie di asterischi nei campi protetti dal masking.
Quindi, anche in caso di riuscito data breach, l’intruso non autorizzato non sarà in grado di recuperare il contenuto originale delle informazioni mascherate, e – al più – avrà estratto una lista di campi asteriscati di nessun valore, come da esempio riportato qui sotto:
Molto utile per tracciare in modo approfondito ed esaustivo le attività svolte a sistema è la soluzione UI Logging.
Ad ogni scambio di informazioni Andata/Ritorno (Front-end > Server > Front-end) viene associata la generazione di un Log.
Il Log è strutturato per contenere i metadata relativi all’accesso (quindi nome utente, IP, timestamp, etc…) e il contenuto visualizzato o elaborato dall’utente, salvato in accoppiate campo/valore.
L’analisi dei log può avvenire in real-time (previa configurazione di messaggi di alert e notifiche), oppure on-demand sfruttando i potenti filtri che il Log Analyzer mette a disposizione.
Per realtà aziendali con elevati volumi di log generati è possibile automatizzare l’analisi dei log mediante l’integrazione con Enterprise Threat Detection (ETD).
SAP ETD è in grado di identificare in modo tempestivo e affidabile tentativi di attacco provenienti da fonti interne o esterne.
Basata sulla funzionalità Smart Data Streaming di HANA, ETC legge, analizza e invia notifiche di allarme in real-time, fin dalla ricezione del dato in ingresso dai sistemi connessi.
I Log contenenti attività sospette, vengono vagliati sulla base di pattern noti, e riconosciuti come potenziale minaccia alla sicurezza del sistema.
Con l’introduzione del GDPR, in caso di attacco informatico e /o fughe di dati, le aziende hanno l’obbligo di notificare entro 72 ore (e comunque “senza ingiustificato ritardo”) l’avvenuto Data Breach all’Autorità Garante e alle persone fisiche interessate.
E una corretta e calibrata implementazione di SAP ETD si pone appunto in questa direzione, assolvendo il requisito normativo.
CAPITOLO 5
Come proteggere i sistemi di Test (Masking Vs Scrambling e SAP TDMS)
E’ buona prassi limitare il ricorso a dati personali ai soli ambienti in cui sono – realmente- necessari, ossia all’interno dei sistemi di produzione.
Purtroppo, nella realtà accade spesso che i dati personali delle persone fisiche siano replicati in svariati ambienti non-produttivi per via di copie sistema (refresh) dei corrispondenti sistemi produttivi.
In un complesso landscape, si stima che che un dato personale possa essere copiato fino a 7 volte nei vari sistemi di Sviluppo, Quality, Sandbox, Pre-Produzione (ERP, CRM, SRM, BW, etc…).
Un eventuale data breach in un sistema non-produttivo avrebbe, pertanto, le stesse conseguenze di un attacco alla produzione.
Naturalmente è possibile estendere ai sistemi non produttivi le stesse logiche di protezione applicate nell’ambiente produttivo (quindi GRC, Access Control, Process Control, UI Masking, UI Logging, ETD…), ma sarebbe oltremodo dispendioso e complesso.
Negli ambienti di sviluppo, test e pre-produzione si raccomanda invece di implementare tecniche di mascheramento, anonimizzazione o pseudonimizzazione, in cui dati personali vengono privati del loro contenuto informativo.
Ad esempio, con una pseudonimizzazione ad hoc applicata ai dati personali presenti nei soli sistemi non-produttivi, è ragionevole attendersi una riduzione fino ad anche il 70% di tutti dati soggetti a regolamentazione GDPR.
Prima di addentrarci nei dettagli delle soluzioni disponibili, occorre fare un po’ di chiarezza sulla terminologie tornate in auge con l’avvento della GDPR:
- Masking (o offuscamento)
- Anonimizzazione
- Pseudonimizzazione (o tokenizzazione)
- PII Intelligent Mapping

Abbiamo già incontrato la tecnica del Masking nella soluzione UI Masking (o SAP Field Masking) applicata al sistema produttivo.
Ad esempio, un classico esempio di data Masking è un numero di telefono personale di cui viene impedita la completa visualizzazione nel front-end:
Dato nel back-end system (a livello DB):
- Numero di Tel. +39 333 444 55 66
Dato nel front-end (per gli utenti NON autorizzati alla visione in chiaro):
- Numero di Tel. +39 333 444 ** ** (con Masking parziale sulle ultime cifre)
Oppure:
- Numero di Tel *** *** *** ** ** (con Masking completo)
Il masking è indicato specialmente in ambienti produttivi per proteggere i dati personali dagli user che non hanno autorizzazione alla visione.
Naturalmente è necessario mantenere anche l’accesso al dato in chiaro per gli utenti autorizzati alla processazione per finalità di business.
Anonimizzazione, Pseudonimizzazione e PII Intelligent Mapping sono invece delle tecniche di Data Scrambling, in cui il dato originario viene modificato direttamente a livello di Database e sostituito rispettivamente con:
- un Valore Fisso (es. ANONIMO)
- un Token linkato al valore originario (es: Ex6gJtH)
- uno Pseudonimo Verosimile ma non reale (es. il nome proprio “Marco” convertito in “Giulio”).
La seguente tabella aiuta a chiarire meglio la differenza tra i metodi di scrambling:

Pseudonimizzazione e Anonimizzazione sono due termini distinti, che sono però spesso confusi nel mondo della sicurezza dei dati. E’ essenziale capirne la differenza, dal momento che dati anonimi e dati pseudonimizzati rientrano in categorie diverse del regolamento.
Pseudonimizzazione e anonimizzazione differiscono in un aspetto chiave:
L’anonimizzazione – applicata a tutti i dati personali di una persona fisica – cancella irreversibilmente la possibilità di risalire all’identità originale.
Nella tabella qui sopra, l’utente “ANONIMO” è assegnato indistintamente sia a Michele, sia a Francesco, sia a Stefano: è chiaramente impossibile scoprire l’identità nascosta nei record così anonimizzati.
La pseudonimizzazione sostituisce invece l’identità dell’interessato con un nuovo valore (anche con un token apparentemente indecifrabile), lasciando aperta tuttavia la possibilità di ri-identificare la persona fisica originale, sia direttamente (mediante una tabella di trascodifica), sia indirettamente (ad esempio evitando di mascherare altri dati personali che consentano di derivare l’identità del soggetto).
Nell’esempio tabellare, il nuovo “nome” rQgk8WX è associato esclusivamente al nome originale “Michele”.
Mantenendo l’informazione del legame in una tabella di trascodifica (Old Value = “Michele”, New Value = “rQgk8WX”) è sempre possibile per il DPO tener traccia delle transazioni fatte da “Michele” (o meglio dal suo nuovo pseudonimo “rQgk8WX”).
Infine, la tecnica di scrambling P.I.I. Intelligent Mapping consiste in una Pseudonimizzazione (o Anonimizzazione) Intelligente, appunto.
Semplicemente, si sostituiscono i dati personali originali con dei dati personali fittizi (generati casualmente dall’Intelligenza Artificiale) che non sono reali, ma verosimili.
E’ un po’ come essere al cinema, dove gli attori interpretano personaggi inesistenti ma realistici.
Ciò consente una piena operatività dei sistemi di test e la possibilità di sottoporre i dati ad analisi statistiche tutelando la privacy delle persone fisiche reali.
Per un approfondimento su PII Intelligent Mapping rimando al blog “GDPR e SAP: anonimizzare i dati personali in modo intelligente (e simile al vero)”.
E’ giunto il momento di introdurre lo strumento principe che SAP mette a disposizione per la protezione dei dati personali nei sistemi non produttivi: SAP Test Data Migration Server (SAP TDMS)
SAP TDMS (Test Data Migration Server) è il software della galassia SLO (System Landscape Optimization) ideato appositamente per la creazione e refresh intelligenti di sistemi non-produttivi.
Il TDMS nasce e si sviluppa appunto con lo scopo di creare sistemi non produttivi con volume di dati ridotti e recenti (fresh data), estratti dai corrispettivi sistema produttivi.
Anziché ricopiare l’intero volume di un ambiente produttivo su un sistema di test, si è pensato di copiare i dati transazionali creati solo a partire da una certa data in avanti (From-Date).
Per esempio, supponendo di avere un sistema produttivo con 10 anni di storia, è possibile impostare una from-date per estrarre le transazioni avvenute solo nell’ultimo anno (data > GG.MM.AAAA), limitando proporzionalmente il volume di dati trasferiti nel sistema di Test.
Lo scopo raggiunto è quello di assicurare dati recenti e sempre aggiornati negli ambienti di test, minor volume (= minor TCO), maggior velocità di copia, e più alta frequenza delle copie.
Nel corso del tempo, il TDMS si arricchisce via via di nuove funzionalità, tra le quali, la capacità di data scrambling (che è poi quella che ci interessa in ottica GDRP).
Mi spiego meglio: contestualmente all’estrazione dei dati dal sistema produttivo, il TDMS è in grado – grazie al suo motore data scrambling – di applicare regole di anonimizzazione / pseudonimizzazione su campi pre-impostati (e quindi anche sui campi contenenti dati personali).
Ho avuto modo personalmente di applicare le logiche di pseudonimizzazione dei dati personali all’interno di un progetto TDMS con scrambling scenario per GDPR.
CAPITOLO 6
Come gestire il Diritto all’Oblio (con SAP ILM)
L’ultima proposta SAP – ma non meno importante delle altre – che va presa in considerazione nell’ambito di un progetto GDPR è SAP ILM (Information Lifecycle Management).

La soluzione ILM è stata concepita con l’intento di migliorare la prontezza e la performance del sistema SAP attraverso il potenziamento delle funzionalità di archiviazione dei dati obsoleti su uno storage esterno.
Semplificando, ILM può essere vista come un’evoluzione della transazione SARA (per chi la conosce), con la possibilità di gestire anche complesse logiche di ritenzione del dato obsoleto (imposte da varie esigenze normative e legali), prima della sua distruzione fisica, una volta raggiunto il fino scopo.
Tra le varie funzionalità ILM cito:
- Archiviare dati obsoleti per migliorare le prestazioni e ridurre le dimensioni del database (e relativi costi di amministrazione)
- Supportare Regole di Ritenzione dei dati tramite archivi separati basati su diverse esigenze temporali
- Ridurre i costi di gestione IT con il consolidamento di sistemi e smaltimento (decommissioning) dei sistemi legacy
- Garantire l’accesso per verifica della conformità e reporting sui sistemi dismessi
- Riduzione dei costi e dei rischi di azione legale, con l’automatizzazione del recupero dati in oggetto
In ottica GDPR le logiche ILM ben si adattano alla gestione di uno degli articoli fondamentali introdotti dalla normativa:
il diritto alla cancellazione (diritto all’Oblio) di cui riporto l’incipit, e che vi invito a leggere nella sua interezza:
Art. 17 GDPR: Diritto alla cancellazione («diritto all’oblio»)
- L’interessato ha il diritto di ottenere dal titolare del trattamento la cancellazione dei dati personali che lo riguardano senza ingiustificato ritardo e il titolare del trattamento ha l’obbligo di cancellare senza ingiustificato ritardo i dati personali, se sussiste uno dei motivi seguenti:
- i dati personali non sono più necessari rispetto alle finalità per le quali sono stati raccolti o altrimenti trattati;
- l’interessato revoca il consenso su cui si basa il trattamento…
Pertanto, attraverso ILM è possibile gestire l’archiviazione dei dati personali obsoleti (quindi di anagrafiche con dati personali e relative transazioni collegate) fino alla cancellazione fisica degli stessi, una volta superati i tempi legali e normativi di ritenzione. Per esempio, possiamo gestire con ILM i dati di ex-impiegati che hanno cessato il rapporto di lavoro con l’organizzazione, oppure di ex-clienti (persone fisiche) cha hanno scelto un altro fornitore.
Conclusioni
Non esiste un unico strumento, sotfware o soluzione per garantire la conformità al GDPR.
La compliance si persegue attraverso la collaborazione sinergica tra i vari dipartimenti dell’organizzazione aziendale e il corretto mix di documentazione e soluzioni software a corredo, insieme alla consulenza degli esperti.
Nella mia esperienza di progetti GDPR in ambito SAP ho avuto modo di implementare, toccare con mano e vedere applicate le soluzioni che ho descritto:
SAP GRC, Access Control, Process Control, UI Masking & Logging, ETD, TDMS e ILM.
Se sei interessato ad approfondire l’argomento contattaci e scopri come possiamo aiutare il Tuo Business.
.png&w=3840&q=75)
.png&w=3840&q=75)
